Anbefalinger rundt Webservice
Fellestjenesten fokuserer på teknologi kalt Webservice (WS), og anbefaler denne teknologien for å dele data.
Hva er en Webservice?
En Webservice (WS) er en del av en tjeneste som tilbyr et standardisert grensesnitt (API) for å lese- og/eller skrive tjenestens data. WS bruker web-basert teknologi, som HTTP. En WS kan være en del av tjenesten eller en løsrevet komponent med eget livsløp.
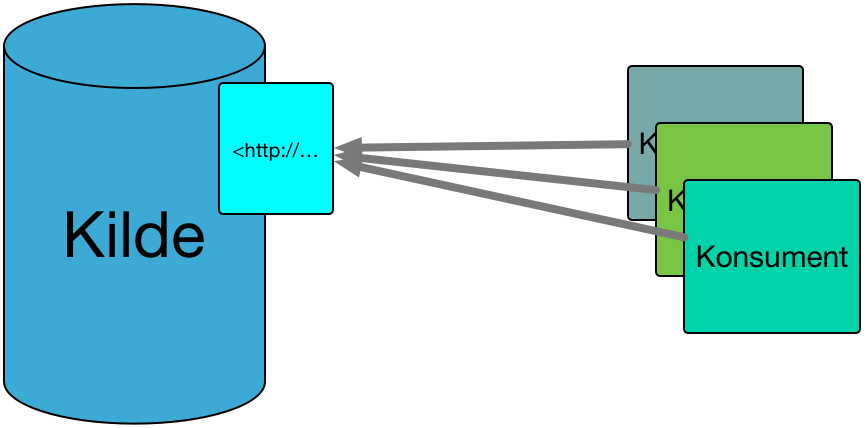
Konsumenter spør kildens WS om data. Flere konsumenter kan benytte samme WS.
En WS-basert modell
Datatilbydere er ansvarlig for å tilby sine data gjennom et API, som konsumenten kan bruke. Konsumentene får kun tilgang til de funksjonene som avtales på forhånd.
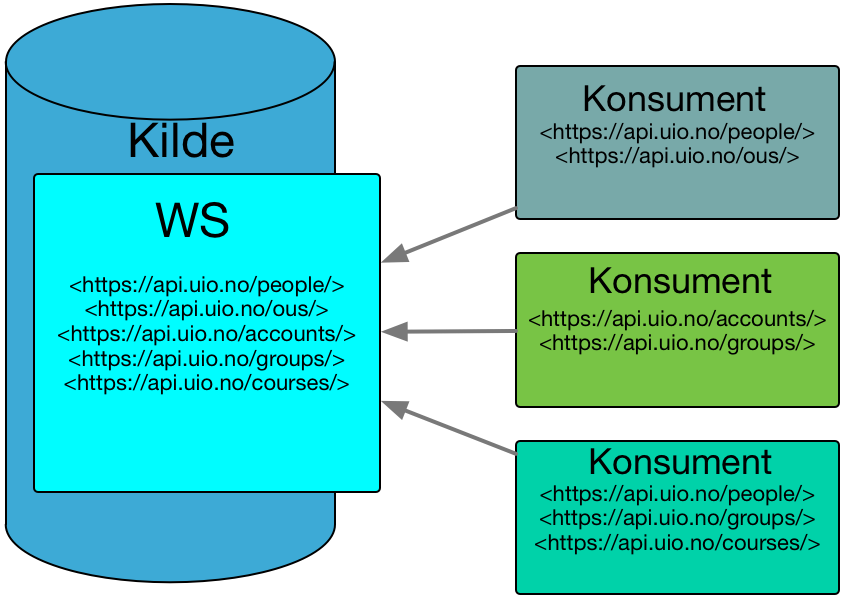
API-et bør utformes med fokus på hva som er virksomhetens data, og forenkles der det er mulig. API-et må for eksempel ikke eksponere interne datastrukturer, men noe som er forståelig og funksjonelt for utenforstående. Interne data, som ikke er interessante for andre, eksponeres ikke.
API-et bør også utformes etter hva som er de generelle behovene, og ikke behov/ønsker som gjelder en enkelt konsument. Spesialtilpasninger bør ligge hos konsumenten og ikke datatilbyder.
I etableringen av en WS-basert integrasjon vil kostnaden knyttet være likt eller dyrere sammenlignet med andre måter å integrere på (for eksempel filbasert eller leverandør-spesifikk svart-boks-integrasjoner). Det er når WS-en allerede tilbyr et rikt API at datatilbyde vil se gevinsten: Konsumenter kan selv skaffe data gjennom WS-en, uten å trenge spesialtilpasninger fra datatilbyder. En bonuseffekt er at konsumenter ikke trenger å måtte vente på utvikling hos datatilbyder.
Meldingskø (MQ)
En meldingskø (MQ) er en tjeneste som gir kilder mulighet til å sende beskjed om at data er endret. I eldre integrasjoner baserer man seg ofte på fulldumper – altså filer med alle data en konsument trenger. Dette er kostbart, sårbart og tregt. Med en meldingskø er tanken at en kilde sender ut en notifikasjon når data har endret seg, som kan være av interesse for konsumenter. Notifikasjonen er ikke nødvendigvis informasjonsbærende nok til at konsumenten kan foreta en endring, men forteller konsumenten at den må hente data på nytt for å sjekke egne data mot den autoritative kilden. Dette gjøres med en lenke til det berørte objektet.
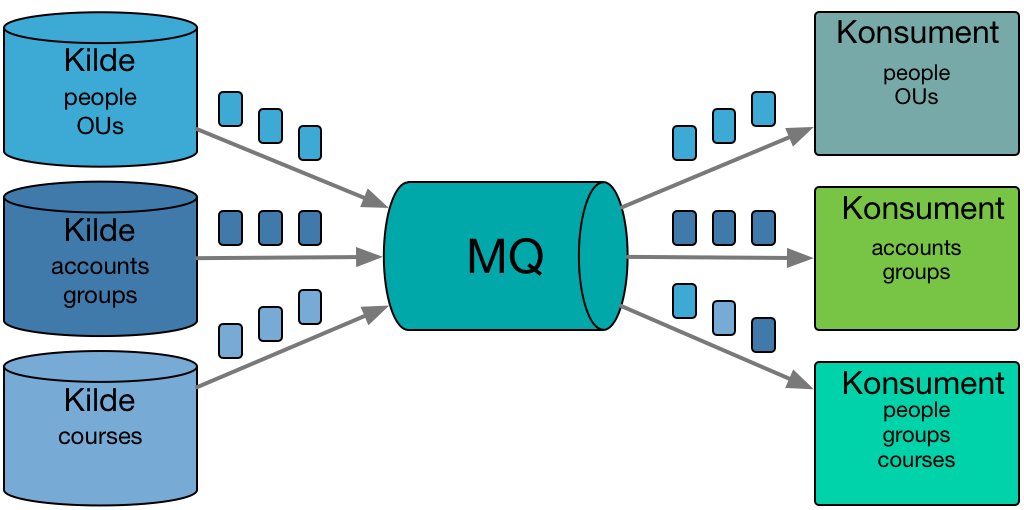
Notifikasjoner sendes fra kildene inn til meldingskøen. Konsumentene velger selv hvilke notifikasjoner de ønsker å abonnere på.
Notifikasjoner skal ikke inneholde utfyllende informasjon, av flere grunner:
-
Færre personopplysninger i notfikasjoner forenkler tilgangsstyringen. Spesielt personopplysninger som krever ekstra beskyttelse ville kunne skapt utfordringer for meldingskøer.
-
Notifikasjonene blir mindre tidskritiske, då konsumenter blir tvunget til å hente korrekt og oppdatert informasjon fra datatilbyders API. For eksempel unngår du at en gammel notifikasjon om at et objekt har blitt slettet ville ført til at konsumenten slettet objektet - det kan hende at objektet i mellomtiden har blitt gjenopprettet.
-
Dette er et enkelt integrasjonsmønster som spesielt passer for provisjoneringer.
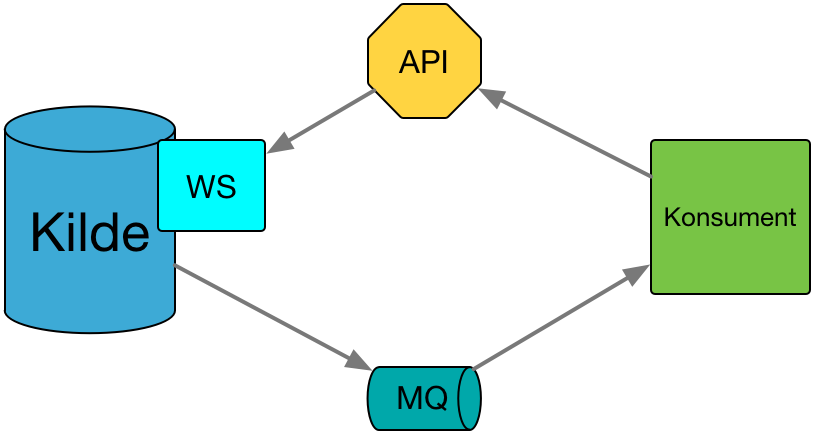
Kilden sender en notifikasjon til en meldingskø som videresender denne til konsumenter som abonnerer på denne typen notifikasjoner. Notifikasjonen sier at konsumenten må hente data om en entitet for å se om endringen skal reflekteres i konsumenten.
Autoritativ kilde
Datatilbydere bør i utgangspunktet bare tilby data de er autoritative for, som vil si at det er denne tjenesten som eier denne typen data hos institusjonen
- såkalt masterdata eller kildedata. Eierskapet besluttes av institusjonen selv.
Dette betyr at WS-en i utgangspunktet bare bør eksponere data som tjenesten er autoritativ for. Det sier også at konsumenter må hente data frå autoritativ kilde, og ikke via andre tjenester. Unntaket er velbrukte katalogtjenester der data tilbys på vegne av andre datatilbydere.
Hvem må ha en WS?
Ikke alle tjenester må ha en WS. Kravet om WS inntreffer hovedsaklig når en kilde sitter på data som andre tjenester burde hatt tilgang til. Har kilden svært få integrasjoner og dette ikke vil øke i fremtiden så vil integrasjonsarkitekturprinsippene heller ikke kreve en WS foran kilden. Det gir for lite avkastning på investeringen.
WS vil enten være påkrevd eller svært nyttig der tjenesten er en autoritativ kilde for data som andre trenger innsyn i, eller der tjenesten fungerer som en del av en annen tjeneste.
Datalager
Integrasjoner er ikke alltid det å flytte data fra A til B, såkalt replisering. Sammensatte tjenester der man utnytter en tjenesteorientert arkitektur vil kunne bygge på andre tjenester. En tjeneste kan for eksempel bruke en annen tjeneste som sitt datalager. I stedet for å replikere data fra kilden, og sette opp en database for det, kan tjenesten heller bruke kildens WS direkte.
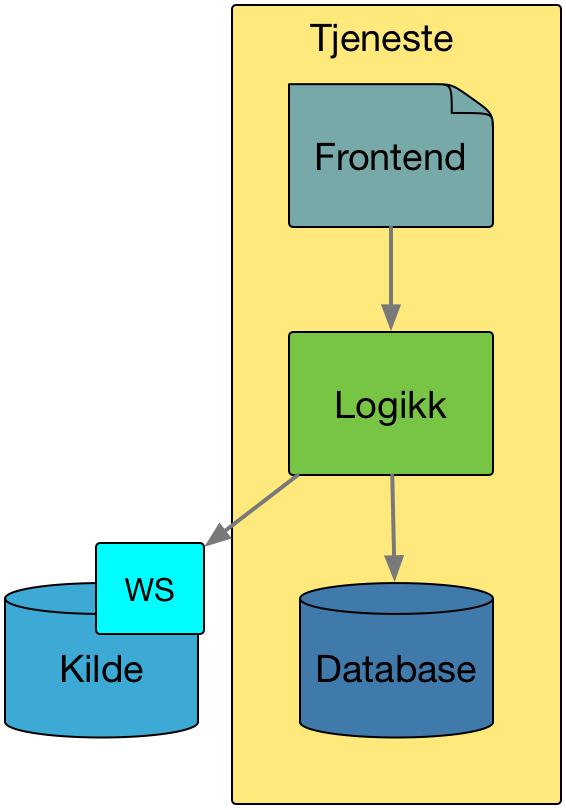
En tjeneste, bestående av et brukergrensesnitt, et logisk lag og en database, benytter en ekstern kilde som en del av sitt datalag.
Å bruke en WS som et datalager kan gjøre det enklere, raskere og mindre kostbart å bygge nye tjeneste, men også en mindre komplisert arkitektur. Ulempen er at det setter høyere krav til kildens oppetid, ytelse og skalerbarhet.
Hvordan skal et API i en WS se ut?
RESTful
REST er en metodikk for å sikre løse koblinger mellom to tjenester i en integrasjon. Selv om REST ofte benytter HTTP som den underliggende protokollen for integrasjonen, er ikke REST begrenset til dette.
For å sikre at man ikke viderefører gamle, tett koblede integrasjoner i den nye integrasjonsarkitekturen, bør tjenesteeiere og -utviklere etterstrebe å lage grensesnitt som er så RESTfulle som mulig.
Så hva er RESTful? Det kan deles inn i fire nivåer, der det er opp til datatilbyder og -utvikler å bestemme hvor RESTful API-et skal være. Anbefalt minimumsnivå er nivå 2.
Nivå 0: RPC over HTTP
På dette nivået ligger REST API-er som ikke egentlig er REST. Man har implementert typiske RPC-kall over HTTP og kaller dette REST. Det resulterende API-et blir spesialisert og lite gjenbrukbart. Typisk forsøker man å tilby funksjonalitet i API-et tatt helt bokstavlig fra en bestilling. Ønsker konsument en å hente fornavn på en person så lager man en funksjon for dette. Konsument to ønsker hele navnet så da lager man en ny funksjon. Konsument tre ønsker en liste med alle navnetyper, samt muligheten til å oppdatere navn så da lages det flere funksjoner for alt dette. Data blir tilgjengeliggjort, men man ender opp med tette koblinger og lite til ingen gjenbruk.
Nivå 1: Ressurser
På nivå 1 begynner man å omfavne RESTful. Isteden for spesialiserte kall for enhver handling som omhandler en ressurs eller entitet så samler man disse i en felles ressurs. I eksemplet med navn på en person fra nivå 0 så samler man navn under stien/endepunktet persons/mathias/names. Under dette området samler man de funksjoner som omhandler navn.
Dette er en bedre løsning enn i nivå 0, men fortsatt utsatt for spesialiserte funksjoner og manglende gjenbruk. Vi anbefaler en ressursdrevet (datadrevet) modell der ressurser i form av data bestemmer mer av strukturen på API-et heller enn en mer tilfeldig modell basert på hvem som spurte om hva når.
Nivå 2: HTTP verb
På dette nivået har API-et modnet betraktelig. Om man implementerer et nivå 2 API så er ikke API-et fullt ut RESTful, men det er likevel av en slik kvalitet at det oppfyller kravene fra fellestjenesten for datadeling. Det vil være modulært, datadrevet og gjenbrukbart.
Vi utvider eksemplene med personnavn fra nivå 1 med at HTTP-verbet bestemme operasjonen man gjør på navn. GET persons/mathias/names vil gi en liste URL-er med de navn som er registrert for personen "mathias". En endring eller sletting gjøres med HTTP-verbene DELETE, POST eller PUT. Behovet for spesialiserte funksjoner blir minimalt da dataene selv representeres som ressurser og man kan lese og skrive til disse ressursene.
Nivå 3: Hypermedia Controls/HATEOAS
For et ekte RESTful API så skal API-et i WS-en være den kontrollerende aktøren i integrasjonen. Dette vil si at i eksemplet med navn så vil utseendet på API-et endre seg i forhold til kontekst. For konsument 1, som kun skal hente fornavn på personer, så viser API-et kun dette. For konsument 3, som ønsker alle navnetyper, samt mulighet til å oppdatere navn, så vil kallet som returnerer listen også inkludere lenker til hvordan konsumenten kan oppdatere navn. For de navn som ikke finnes vil det bli sendt med lenker til hvor konsumenten kan opprette disse navnene. API-et gir fra seg informasjon om tilstanden på data og tilgangene konsumenten har til data. Dette gir navn til det velklingende akronymet HATEOAS (Hypertext As The Engine Of Application State).
Å implementere et ekte RESTful API er ressurskrevende. Det er ofte ikke verdt den ekstra innsatsen å ta steget fra nivå 2 til 3, da nivå 2 gir det største hoppet i gevinster i datadeling. Nivå 3 kan gjøre det enklere å lage nye konsumerende tjenester, men det er også en fare for at datatilbyderen begynner å lage spesialtilpasninger per konsument hvis det ikke implementeres riktig.
Entitetsbasert API
Entitet- eller ressursbasert, som nevnt under nivå 1 under RESTful, handler om å bevege seg bort fra operasjonen man skal gjøre og heller se på data man skal gjøre noe med. Mange uttrekk og funksjoner i dag er resultatet av at man skal gjøre noe bestemt. Konsumenter trenger sammensatte uttrekk fra konsumenter og skal ikke ha for mye eller for lite data. Dataene skal formateres på bestemte måter og svært sjeldent kan to ulike konsumenter benytte de samme uttrekkene.
Å si at API-er skal være entitetsbaserte (evt. ressursbaserte) vil si at man heller eksponerer typiske entiteter fra kilden heller enn ferdige uttrekk. Om en konsument trenger informasjon om ansatte og deres organisasjonstilhørighet så kan dette realiseres med entitetene employeesog organisational units. Relasjonen mellom den ansatte og organisasjon realiseres som attributter i en eller begge entiteter. Det er opp til eiere, forvaltere og utviklere for en kilde om hva som er en entitet eller ressurs. Eksempelvis kan man si at en brukerkonto er en entitet, mens et brukernavn kun er et attributt ved denne brukerkontoen. En gruppe er en entitet, mens gruppenavnet og medlemskap er attributter til gruppen.
For funksjoner som aldri kan være datadrevne – som start/stopp-funksjonalitet – er det opp til tjenesteeier for hvordan man realiserer dette.
Funksjonelt API
Et funksjonelt API, til forskjell fra funksjonell programmering, omhandler at designet av API-et skal være forståelig og brukbart for utenforstående. Utviklere av konsumenter sitter ikke med den domenekunnskapen som de som jobber med en kilde gjør. Dette betyr at API-er inn mot kilder bør forenkles slik at de gir mening for utenforstående, men ikke mer enn at informasjon som er nødvendig for konsumenter går tapt.
Et eksempel kan være den aktive studentmassen på institusjonen. Ulike konsumenter kan være interessert i ulike mengder studenter slik at API-et må gi et rikt utplukk studenter, men konsumentene vet ikke reglene som omhandler betalt semesteravgift, oppmeldt studieprogram eller enkeltemne, samt andre regler som bestemmer om studenter regnes som "aktive" studenter. API-et må kunne realiseres som enten å ha et attributt som sier "aktiv" på ressursen student, eller eksponere alle tilhørende attributter som avgjør om studenten er aktiv i andre enden av skalaen. Sannsynligvis ligger den beste løsningen et sted i midten, der man bør eksponere mye av de tilhørende data, men på en slik måte at konsumenten kan forstå informasjonen heller enn å lære seg de interne strukturene i kilden.
Her kommer referansearkitekturen sin føring på indre og ytre API til nytte: Indre API vil nødvendigvis eksponere flere attributter, mens ytre API forenkler etter hvilken kontekst det lages for. For eksempel vil et indre API eksponere alle attributtene som ligger til grunn for om en student er aktiv, mens et ytre API kanskje bare eksponerer aktive studenter, eller gir et enkelt flagg som forteller at studenten er aktiv.
Hvorfor anbefale Webservice?
Hensikten med å bruke en WS-basert integrasjonsarkitektur er primært å kvitte seg med flaskehalser i organisasjonen og forhindre dobbeltarbeid. Dette er sammenlignet med hvordan mange integrasjoner er gjort tidligere.
Hub & spoke-modellen
En Tidligere integrasjoner basert på en såkalt "hub&spoke"-modell der datakilden er ansvarlig for å levere fra seg de data som en konsument trenger. Årsakene til at dette har blitt en så vanlig modell for integrasjon er mange, der de viktigste er:
- sikkerhet - kun de ansvarlige for kilden skal få tilgang til dataene i kilden
- kompleksitet - kun de ansvarlige for kilden forstår datamodellen i kilden
- sentralisering - som en følge av sentralisering av data så blir integrasjonene også sentraliserte
- tradisjon - slik at man "alltid" gjort integrasjon
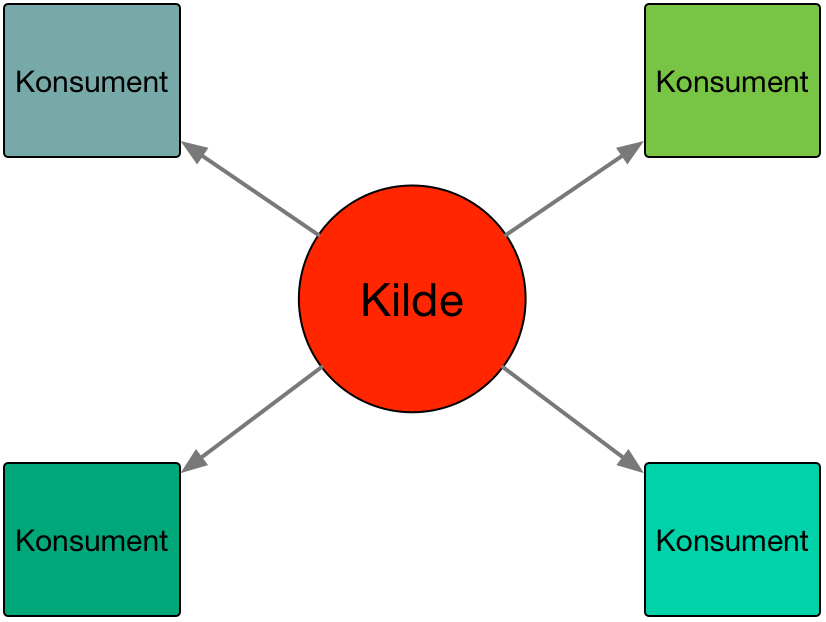
Kilden er ansvarlig for å gi konsumentene data. Ofte gjøres dette ved at komponenter i kilden genererer filer som sendes til konsumenten*.*
Det er store utfordringer knyttet til en slik "hub&spoke"-modell. Sentralisering av data er et veldig fornuftig valg for å bekjempe dårlig datakvalitet og sikre en autoritativ kilde som konsumenter kan forholde seg til. Sentralisering av integrasjonene nyter ikke de samme godene:
- De tekniske ressursene tilknyttet kilden blir bundet opp i enkeltprosjekter, andre prosjekter må vente.
- En endring ute i en konsument medfører at ressurser må endre på kilden.
- Kilden må alltid ha mange tekniske ressurser tilknyttet for å klare arbeidsmengden.
- Prosjekter får store skjulte kostnader fordi ressurser i kilden må gjøre integrasjonen.
- Prosjekter blir forsinket da det sjelden er nok tekniske ressurser tilknyttet kilden og ingen andre enn disse ressursene kan gjøre integrasjonen.
To av problemene som har medført at "hub&spoke"-modellen har blitt så utbredt er sikkerhet og kompleksitet. Uten grensesnitt som adresserer disse problemene så vil det være vanskelig å gjøre en omfattende endring i hvordan UiO gjør integrasjon. Sikkerhetsproblemet består i hovedsak at systemeiere ikke vil tillate andre tilganger rett i databaser eller til API-er inne i tjenesten. Det er lite eller ingen tilgangskontroll så skal noen ha tilgang til noe så får de det til alt - gjerne også muligheten til å endre data.
Kompleksitetsproblemene er ofte at internt i en tjeneste så er data strukturert på en slik måte at de gir mening for systemeiere og ressurser tilknyttet tjenesten, men ikke utenforstående. Så selv om man gir tilgang til en kilde så betyr ikke det at konsumenten skjønner hva kilden tilbyr eller får gale data.