API som datalager
Integrasjonsmønsteret der et API brukes som backend for en frontend-tjeneste.
Dette er et integrasjonsmønster for å gjøre presentasjonstjenester enklere, og blir muliggjort ved at IT-tjenestene følger en felles integrasjonsarkitektur.
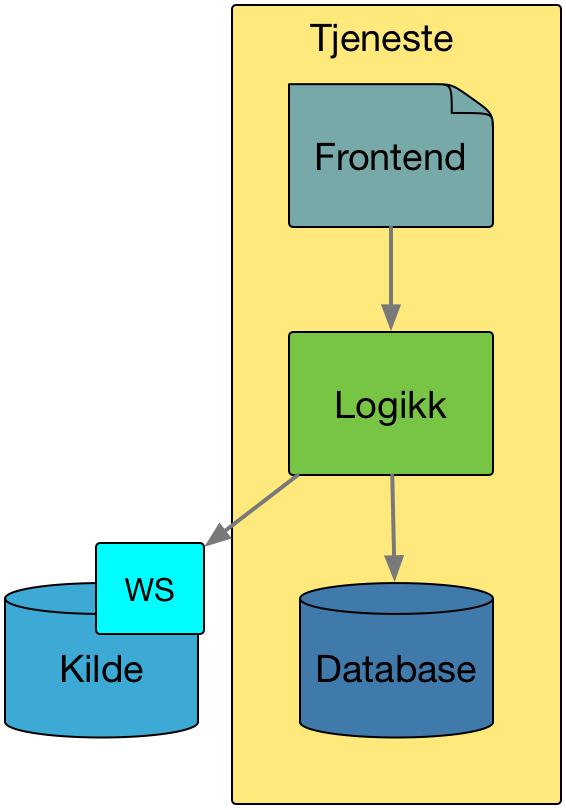
Isteden for at konsumenten kopierer alle data fra datatilbyder til sine interne datalager, så kommuniserer tjenesten med datatilbyders API i sanntid.
En typisk flyt:
- Sluttbruker tar i bruk en tjeneste
- Tjenesten (konsumenten) henter relevant data fra et kildesystem sitt API
- Kildesystemet autentiserer konsument og eventuelt sluttbruker, direkte eller via tredjepart
- Kildesystemet tilgangskontrollerer konsument, og eventuelt også sluttbruker
- Kildesystemet returnerer svaret
- Tjenesten sammenstiller data og viser det fram til sluttbrukeren
Flyten over kan brukes både for system-til-system-integrasjon, og gjennom sluttbruker-involverte protokoller, som Oauth2.
Den samme flyten vil også gjelde når sluttbrukeren gjør endringer på data.
Når bør dette brukes?
Dette mønsteret kan passe for IT-tjenester som er frontendtjenester, for eksempel portalsider på nett som skal samle informasjon fra forskjellige kilder.
Når du ønsker å gjenbruke oppdaterte data i en tjeneste, uten å måtte duplisere alle data.
Eksempler på tjenester:
- Nettportal for studenter, der studenten logger på og får oversikt over sine detaljer, for eksempel informasjon om sine emner (fra FS), undervisningstider (fra kalendersystemet), sine eksamener (fra LMS-system som Canvas), hvor alt dette skjer (fra rombookingssystemet) og sine pensumlister.
Fordeler
- Sluttbrukerne får ferskere data.
- Konsumenten får det enklere, ved å slippe å forholde seg til eget datalager, provisjonering og alt som følger med. For eksempel å slippe å rydde i gamle data. Dette kan gjøre det raskere og billigere for institusjonen å sette opp nye tjenester.
Ulemper
-
Datatilbyder får høyere krav til ytelse og responstid for API-et. Sluttbrukere har ofte lav toleranse for ventetid. Caching bør vurderes.
-
Ressursbruken vil variere veldig avhengig av målgruppen. For eksempel vil studenttjenester ha veldig høy belastning ved studiestart, men veldig liten aktivitet på nattestid.
Fallgruver
-
Konsument må kommunisere med tilbyder om forventninger om last, så tilbyder har mulighet for å skalere opp ved behov.
-
Konsument bør hente data direkte fra kildesystemet og ikke fra et mellomsystem. Hvis ikke kan det kan skape utfordringer når data ikke er korrekte i alle systemer, og det gjør det vanskeligere å få oversikt over all dataflyt hos institusjonen.
-
Datatilbyder er ikke kommunisert godt nok med om forventet last. Økt last vil kunne føre til at API-et går ned og tjenesten slutter å fungere.
Eksempler
- En portal for studentene kan raskt gi studenten en samlet oversikt over data som er relevant for de. For eksempel å hente ut siste nyhetssaker fra påmeldte emner, tidspunkt for neste forelesning og innleveringsfrist, og siste nytt fra sine studentforeninger. Portalen trenger ikke å lagre alle slike opplysninger internt, men hente de fra relevante datatilbydere på direkten.