Teknisk beskrivelse av UiOs integrasjonsarkitektur
En beskrivelse av hvordan UiOs integrasjonsarkitektur ble satt opp, fra 2017.
UiOs integrasjonsarkitektur har implikasjoner for store deler av virksomheten, men mest har den innvirkning på IT-tjenester. Her beskrives de ulike arkitekturkomponentene i integrasjonsarkitekturen, uten detaljer rundt de faktiske tjenestene som er realisert for å understøtte arkitekturen.
Overordnet
Arkitekturen har som overordnet mål om å flytte ansvaret for det å integrere på den part som ønsker å integrere. Tradisjonelt har integrasjoner ofte vært realisert ved at de ansvarlige for en datakilde har måttet generere filer basert på de data de har i kilden, får så å distribuere denne filen. På grunn av krav fra prosjekt eller applikasjonseier som ønsker data, samt et krav om ikke å lekke data, så har disse filene blitt skreddersydd for hver nye konsument. Dette er problematisk av flere årsaker:
- Ansvaret for å integrere ligger da hos de ansvarlige for dataene, ikke de som ønsker dem.
- Neglisjerbar gjenbruksmulighet av slik eksporter.
- Etterhvert som behovet for å integrere flere applikasjoner øker, så øker kompleksiteten i datakilden.
- Prosjekter eller applikasjonseiere kan ikke løse integrasjon selv, de er prisgitt planer og kapasitet hos dem som er ansvarlige for datakilden.
- Å flytte filer er utdatert og ineffektiv teknologi som gir dårlig datakvalitet og brukeropplevelse.
Deler av arkitekturen er organisatoriske grep for å definere ansvar og sette ned regler som hele virksomheten skal følge. Selv de beste IT-tjenestene kan ikke påse at arkitekturen følges – arkitekturen må representeres i forretningssiden i virksomheten også. Siden utenforstående ikke tradisjonelt har hatt tilgang til datakilden, har integrasjoner vært forbeholdt de ansvarlige for kilden. For å endre på dette definerer denne arkitekturen styringsregler som pålegger datakildeeiere/systemeiere å tilby data via åpne grensesnitt.
Modellen
Den overordnede tekniske modellen som ligger til grunn for UiOs integrasjonsarkitektur, er en distribuert modell. Dette betyr at data og ansvar er distribuert i organisasjonen, men liten grad av sentralisering. Det er flere årsaker til at dette er valgt modell, men primært kommer dette av hvordan virksomheten er organisert.
 Tjenester, applikasjoner og systemer er i stor grad selvstendige og ansvarlige for å hente de data de trenger selv.
Tjenester, applikasjoner og systemer er i stor grad selvstendige og ansvarlige for å hente de data de trenger selv.
Modellen er den mest formålstjenlige – organisatoriske – for UiO, men gir også noen utfordringer:
- Økt risiko for varierende teknologi og grensesnitt foran applikasjoner
- Ingen sentral oversikt
- Ingen sentral kontroll
- Ingen gevinster gjennom sentralisering og stordrift
For å adressere disse utfordringene er det definert noen styringsregler og støttestjenester.
Webservice (WS)
En webservice er et teknisk grensesnitt som følger bestemte bransjenormer. Gjennom UiO:IntArk har et sett med styringsregler blitt vedtatt for å standardisere hvordan tjenester og applikasjoner tilbyr grensesnitt. Hensikten med dette er å standardisere der det er hensiktsmessig, uten å begrense handlingsrom og innovasjon ute blant tjeneste- og applikasjonseiere. Det foreligger også en veiledning om hvordan man vurderer en eksisterende WS eller designer en.
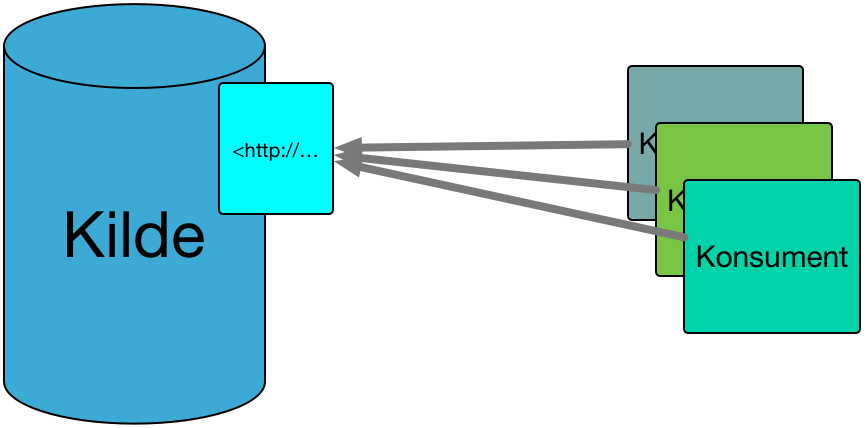 En kilde tilbyr sine data gjennom en WS. Konsumenter gis muligheten til å hente de data de trenger.
En kilde tilbyr sine data gjennom en WS. Konsumenter gis muligheten til å hente de data de trenger.
En WS som tilbyr et RESTful API gir fordeler:
- Bransjestandard
- Gjenbrukbar funksjonalitet
- Fremmer heller enn hemmer innovasjon
API manager
En API manager er en tjeneste som har til ansvar å kontrollere tilganger til tjenesters WS-er. Det å implementere full tilgangskontroll til API-er er en anselig ekstrakostnad for applikasjonsforvaltere som skal tilby en WS. Uten tilgangskontroll vil WS-en tilby alle data for alle.
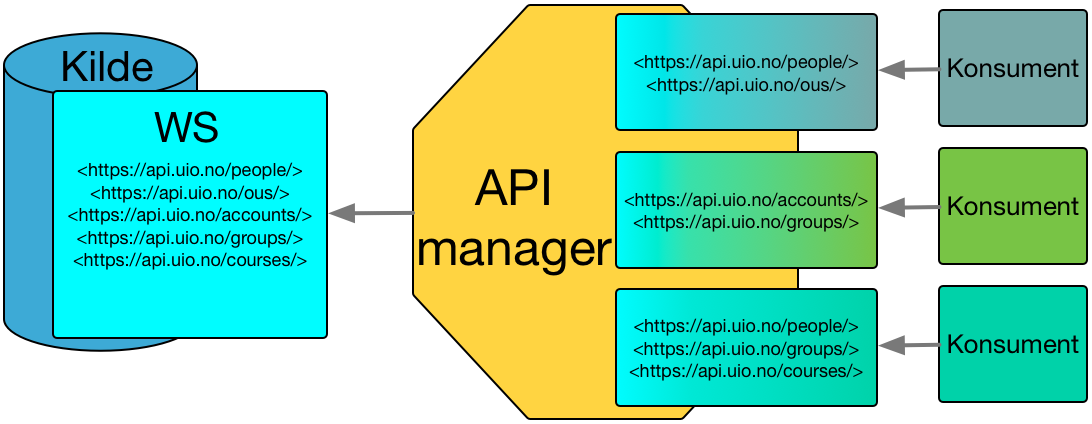 API manager gir begrenset tilgang til et API. De ulike konsumentene får kun tilgang til de delene av API-et som er godkjent gjennom API manager.
API manager gir begrenset tilgang til et API. De ulike konsumentene får kun tilgang til de delene av API-et som er godkjent gjennom API manager.
Tilgangskontroll til hvert enkelt API er en betydelig besparelse for applikasjonsforvaltere som er ansvarlige for WS-er, men det gir også en forenkling og en besparelse for konsumenter:
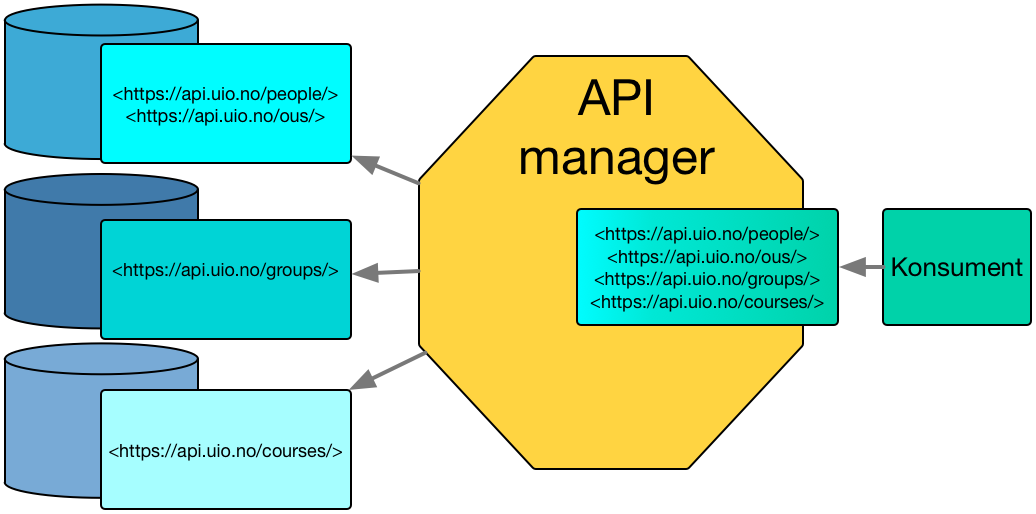 En konsument forholder seg kun til API GW, mens bak GW rutes trafikken til multiple API-er.
En konsument forholder seg kun til API GW, mens bak GW rutes trafikken til multiple API-er.
Fordi all trafikk mellom WS og konsument går gjennom API manager så adresserer man flere av utfordringene med den valgte modellen:
- Sentral oversikt over integrasjoner
- Sentral kontroll over integrasjoner
- Stordriftsfordeler ved at tilgangskontroll av tjenester sentraliseres
Gitt retningslinjene for hvordan et API skal utformes så vil man også kunne se hvordan data flyter via integrasjonene.
API manager er tilrettelagt distribuert forvaltning av API-tilganger slik at den organisatoriske modellen etterleves selv om API manager er en sentral komponent. Dette vil si at applikasjonsforvaltere selv forvalter tilganger til API-er og data i API manager.
Meldingskø (MQ)
Meldingskøen – MQ – er en tjeneste for å fortelle om endringer. WS brukes for å hente data (evt. skrive), men dette løser ikke de situasjoner der en applikasjon skal fortelle at en endring har skjedd. Man kunne skissert en løsning der applikasjonen skulle sendt endringen til alle WS-er rundt omkring, men dette er ikke generelt nok og det undergraver prinsippet om å la de som skal integrere, gjøre integrasjonen selv.
Løsningen er å tilby en sentral meldingskø der produsenter sender notifikasjoner om endringer på sine data. Produsenten vet ingenting om eventuelle konsumenter av disse notifikasjonene og forholder seg kun til MQ.
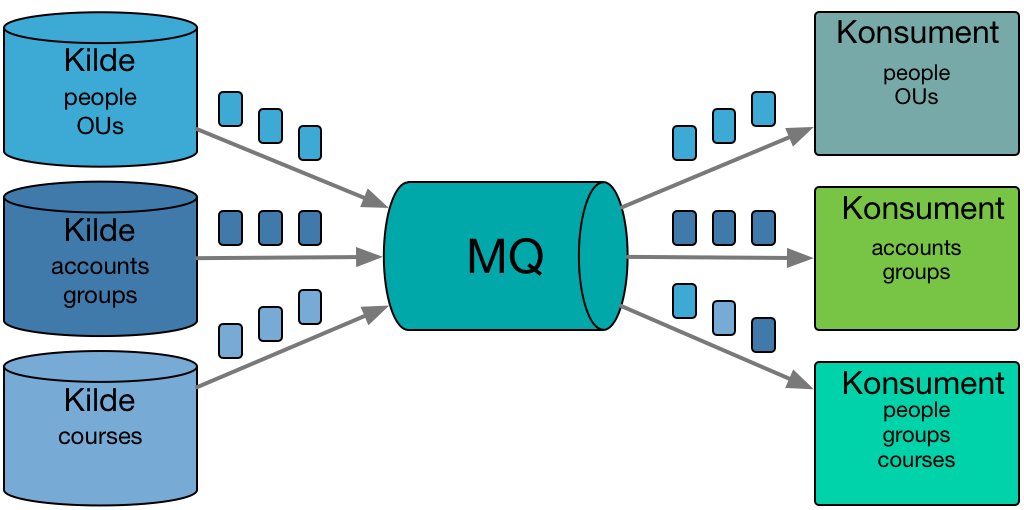 Tre kilder sender inn notifikasjoner til MQ. Tre konsumenter henter notifikasjoner. Konsumenten nede til høyre konsumerer enkelte notifikasjoner fra alle tre produsenter.
Tre kilder sender inn notifikasjoner til MQ. Tre konsumenter henter notifikasjoner. Konsumenten nede til høyre konsumerer enkelte notifikasjoner fra alle tre produsenter.
MQ vil ta ansvar for mye av logistikken rundt notifikasjoner. Hendelses-basert kommunikasjon er komplekst med flere utfordringer:
- Oversikt over alle køer og notifikasjoner
- Tilgang til køer og notifikasjoner
- Oppetidskrav og redundans
MQ løser i stor grad disse problemene og gjør at produsenter kan forenkle notifikasjonsutveksling.
I UiO:IntArk er innholdet i notifikasjoner også regulert. Notifikasjoner sendes typisk ikke ut uten innhold, men for MQ så er notifikasjoner tenkt brukt kun som et varsko på at konsumenter skal undersøke WS for oppdateringer. Det er flere årsaker til dette, men de viktigste er:
- En notifikasjon blir aldri komplett. Data er sammensatte og en endring på et fakultet kan få implikasjoner for tilhørighetene til personer tilknyttet fakultetet.
- Datarike notifikasjoner vil måtte tilgangskontrolleres. Datafattige notifikasjoner kan publiseres nærmest fritt.
En notifikasjon gjennom MQ vil typisk si noe om at en entitet er endret. Det vil være opp til konsumenten å finne ut hva som er endret. Notifikasjonen vil gi indikasjon på hvilken entitet som har endret en type data, men vil ikke lekke informasjon som kan identifisere en person. Notifikasjonene vil heller ikke si noe om tidligere eller nytt innhold i data som er endret.
Hvordan modellen fungerer
Arkitekturen legger opp til å sentralisere tjenester som er nyttige, som ikke begrenser handlingsrommet til applikasjonsforvaltere eller prosjekter, og som effektiviserer integrasjon på UiO. Det er ikke nødvendigvis slik at alle applikasjoner vil måtte forholde seg til alle komponenter i arkitekturen, det er styrt av integrasjonsbehovet for applikasjonen.
Provisjonering – Need to Know
Provisjonering er det å sende en mengde data fra en applikasjon til en annen. Hvorfor man ønsker å gjøre dette kan være mange, men tradisjonelt har man basert integrasjoner på provisjonering fordi integrasjoner har vært tunge, filbaserte batch-oppdateringer. Man har laget store filer med komplette datasett, flyttet disse til konsumenten og der sammenligner man den store filen med konsumentens database for å se etter endringer. Dette er ikke en effektiv måte å integrere på. Isteden kan slik provisjonering være hendelsesdrevne:
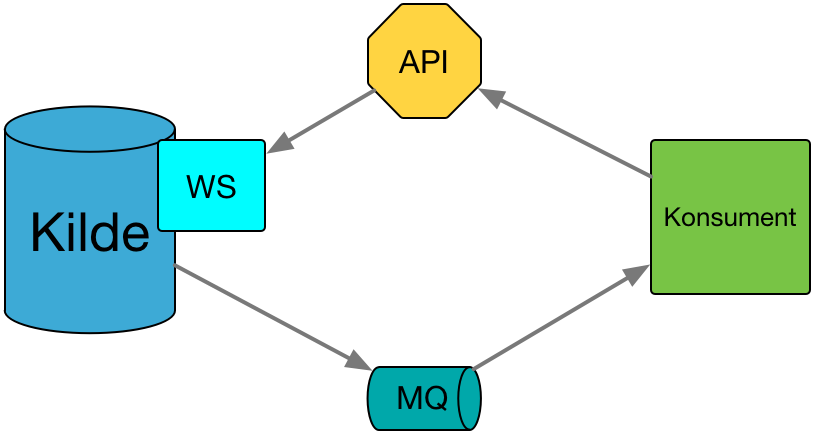 En entitet X oppdateres i Kilde. Kilde sender en notifikasjon til MQ om at entitet X er oppdatert. MQ sender en notifikasjon til konsumenter som abonnerer på denne typen notifikasjoner om at entitet X er oppdatert. Konsument vet ingenting om hva endringer består i, så Konsument kontakter API manager for å få tilgang til Kildens WS for å spørre om data om entitet X.
En entitet X oppdateres i Kilde. Kilde sender en notifikasjon til MQ om at entitet X er oppdatert. MQ sender en notifikasjon til konsumenter som abonnerer på denne typen notifikasjoner om at entitet X er oppdatert. Konsument vet ingenting om hva endringer består i, så Konsument kontakter API manager for å få tilgang til Kildens WS for å spørre om data om entitet X.
Mange applikasjoner, som i dag er baserte på gamle integrasjoner med provisjonering, trenger ikke å provisjonere data i den nye arkitekturen. Likevel er det et behov for provisjonering i de tilfeller der man lager moderne applikasjoner og integrasjoner. Eksempel: Når en ny person registreres i HR-systemet så er ikke HR-systemet ansvarlig for å utstede en brukerkonto til personen. Dette er IAM-kjernen (tidligere BAS, IdM) ansvarlig for. IAM-kjernen vet ikke at det er registrert en ny person i HR-systemet før HR-systemet gir beskjed. IAM-kjernen vil ikke kopiere alle data om personen fra HR-systemet, men den trenger data om personen for å lage en brukerkonto til vedkommende og da vil IAM-kjernen provisjonere noe data. IAM-kjernen vil beholde oversikt over hvem som er eier for brukerkonti f.eks. Disse eierne er provisjonert fra HR-systemet.
Man kan tenke seg et annet eksempel der flyten er lik som i figuren over, men man ikke provisjonerer – integrasjonen er basert på Need to Know. Forskjellen på provisjonering og Need to Know ligger i om konsumenten lagrer kopier av data fra kilden i sine datalagre. Distinksjonen mellom de to er minimal, men generelt skal man forsøke å unngå mellomlagring av data fra et kildesystem og heller hente disse dataene fra kilden ved behov. Av ulike årsaker kan dette vise seg vanskelig så provisjonering vil forekomme også i den nye arkitekturen.
Forskjell fra DiFis eNotifikasjon
Selv om Need to know kan ligne veldig på eNotifikasjon-mønsteret fra DiFis referansearkitektur for datautveksling, er det til dels store avvik i mønstrene:
| Need To Know | eNotifikasjon | |
|---|---|---|
| 1 | Får tilsendt en notifikasjon. Konsumenten kan være tilstandsløs, da konsumenten ikke trenger å ha begrep om hvilke notifikasjoner som er prosessert. | Må hente en liste over notifikasjoner. Konsumenten må lagre tilstand, da eNotifikasjon-mønsteret forutsetter at konsumenter vet hvilke notifikasjoner som er prosessert. |
| 2 | Notifikasjonen inneholder kun nok informasjon til å identifisere hva som har endret seg. Konsumenten må utføre eOppslag mot kildesystem før det kan avgjøres om det skal utføres en operasjon. | Notifikasjonen inneholder informasjon om hva som har endret seg, og en identifikator til et hendelsesdokument som inneholder endrede data. eNotifikasjonen bærer nok data til å avgjøre om det skal utføres en operasjon. |
| 3 | Rekkefølgen notifikasjoner ankommer i er ikke garantert å være velordnet og sekvensiell. | Rekkefølgen notifikasjoner ankommer i er alltid velordnet og sekvensiell. |
| 4 | Ingen autorisasjon er nødvendig da notifikasjoner kun har informasjon om hva som er endret. Produsenter har ikke begrep om hvem som er konsumenter. | Autorisasjon kan være nødvendig da notifikasjoner kan inneholde data. I tilfeller der autorisasjon er nødvendig, må produsenter ha et begrep om hvem som skal kunne konsumere hvilke data. |
| 5 | Need To Know er en implementasjon av Fire And Forget og eOppslag mønstrene. | eNotifikasjon er en implementasjon av Event Sourcing mønsteret. |
Modulære applikasjoner
Integrasjonsarkitekturen legger også opp til mer modulære tjenester som er satt sammen av ulike applikasjoner (eller deler av applikasjoner). Under Provisjonering beskrives en dataflyt mellom to applikasjoner fordi konsumenten skal agere på endringer i produsentens data. Man kan tenke seg scenarier der man ikke anser tjenester eller applikasjoner som så separate, men heller at applikasjoner sammen utgjør en tjeneste.
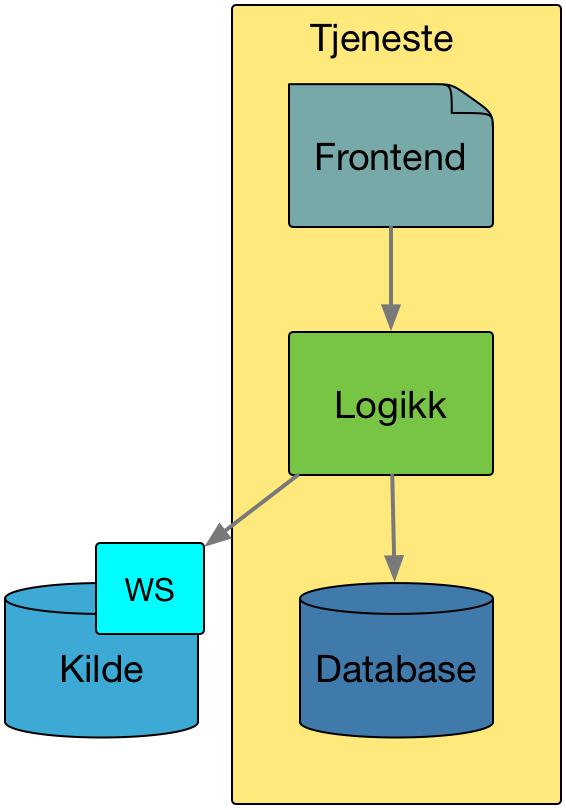 Isteden for å flytte data fra Kilde til sine interne datalager så kommuniserer tjenesten med Kilde i sanntid ved behov.
Isteden for å flytte data fra Kilde til sine interne datalager så kommuniserer tjenesten med Kilde i sanntid ved behov.
Et eksempel på en produsent som vil være attraktiv for mange tjenester er e-posttjenesten. Ved å integrere e-posttjensten i f.eks. læringsplattformen får studenter en bedre og mer innholdsrik arbeidsflate. LMS-et kan benytte e-post- og kalendertjenesten for meldinger mellom studenter og forelesere, eller kollokvie- og undervisningsgrupper. Mer tradisjonell integrasjon ved å kopiere data vil gi dårligere brukeropplevelse og kompleksitetsproblemer ved en eventuell synkronisering mellom LMS-et og e-posttjenesten.
Sammendrag
UiOs integrasjonsarkitektur er en standardisering av prosess og teknikk for å effektivisere integrasjoner. Standardisering er, som kjent, et tveegget sverd. Det strømlinjeformer slik at aktiviteter blir mer effektive, men strømlinjeformingen hindrer også innovasjon og handlingsrom. Tanken bak UiO:IntArk har hele tiden vært å standardisere der det er formålstjenlig og la felt som krever selvråderett være opp til applikasjonsforvaltere, utviklere og prosjekter. Hvaman ønsker å integrere er opp til den enkelte, hvordan man integrerer stilles det krav til.
Det å basere arkitekturen på bransjestandard teknologi og inkludere de organisatoriske utfordringene som noe arkitekturen skal adressere har resultert i en arkitektur som posisjonerer UiO i forhold til bransjen, men ikke på bekostning av autonomi. Arkitekturen vil kunne erstatte protokoller og tjenester etterhvert som bransjen utvikler seg, men uten å måtte omskrive hele arkitekturen. Store systemer kan oppstå og legges ned uten at arkitekturen påvirkes nevneverdig.